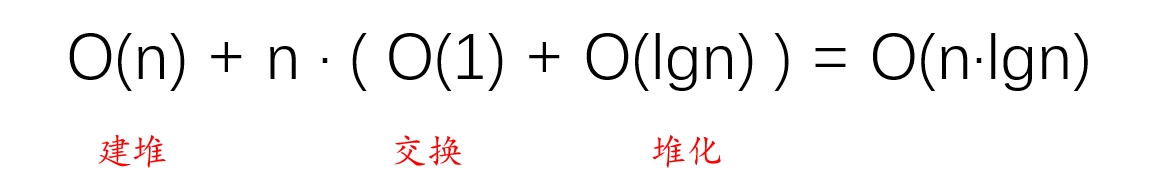# python代码 # A: List of elements in the heap # i: Index of the element to check # n: Total number of elements in the heap defmax_heapify(A, i, n): largest = i # Initialize largest as root left = 2 * i + 1# i's left child right = 2 * i + 2# i's right child
# If left child is larger than root if left < n and A[left] > A[largest]: largest = left
# If right child is larger than the largest so far if right < n and A[right] > A[largest]: largest = right
# If largest is not root if largest != i: A[i], A[largest] = A[largest], A[i] # Swap max_heapify(A, largest, n) # Recursively heapify the affected sub-tree
需要注意:当对 i 节点调用MAX-HEAPIFY()时,只有当其左右子树都是最大堆时,调用后,i 节点开始的树才是最大堆。
直观上,不难发现MAX-HEAPIFY()的时间复杂度是:**O(lgn)**。
建堆
1 2 3 4 5 6 7
# python代码 defbuild_max_heap(A): n = len(A) A.heap_size = n # Set the heap size # Start from the last non-leaf node and move upwards for i inrange(n // 2 - 1, -1, -1): max_heapify(A, i, n)
# python代码 defheapsort(A): build_max_heap(A) # Build the max heap for i inrange(len(A), 1, -1): A[0], A[i-1] = A[i-1], A[0] # Swap the root with the last element A.heap_size -= 1# Decrease the heap size max_heapify(A, 0, i-1) # Heapify the root
# INCREASE-KEY(S, x, k) # 将A[i]赋值为k,并往上逐个检查:是否大于父节点,若大于则交换。 defheap_increase_key(A, i, key): if key < A[i]: raise ValueError("New key is smaller than current key") A[i] = key while i > 1and A[parent(i)] < A[i]: A[i], A[parent(i)] = A[parent(i)], A[i] # Swap with parent i = parent(i) # INSERT(S,x) # 在堆末尾插入负无穷,再调用heap_increase_key()将负无穷变为x,从而实现插入。 defmax_heap_insert(A, key): A.heap_size += 1 A[A.heap_size - 1] = float('-inf') # Set the new leaf node with a very small value heap_increase_key(A, A.heap_size - 1, key)