引言
当数据库中多个事务并发执行时,事务的隔离性不一定能保持。为了保持事务的隔离性,数据库必须控制不同事务之间的互动。
这里我们将介绍两种常见的并发控制(concurrency control)的机制:
- two-phase locking(二相锁)
- timestamp(时间戳)
二相锁
就像“编辑在线文档”,为了避免自己写的内容被其他人篡改,最简单的方式就是:在自己编辑的时候给文档上锁,只有自己能修改其中的内容。等到修改完成后,再打开锁,允许其他人进行修改。
数据库中也是类似的。
什么是锁
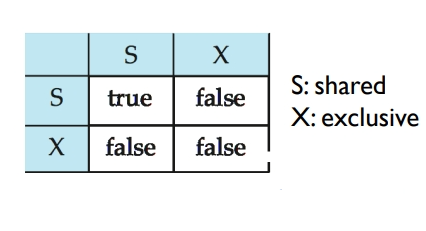
数据项可以被加上以下两种模式的锁:
- 共享锁 shared mode (S):数据项只能被读。
- 排他锁 exclusive mode (X):数据项可以被读或者写。
显然,多个事务可以同时持有同一个数据的共享锁。但若有一个事务持有这个数据的排他锁,那么其他事务不能再持有该数据的共享锁。所以,不同锁之间也是存在兼容性(Lock-compatibility)的。
当一个事务想访问一个数据时,它会向并发控制管理器(concurrency-control manager)发出请求。如果当前不存在与其不兼容的锁,则向该事务授权新锁;否则需要等待不兼容的锁全部被释放,才能再授权新锁。
基于锁的协议
但需要注意:上锁并不能保证调度是可序列化的。
例如:A账户有100元,B账户有200元;T1是从B向A转账50元,T2是打印A、B账户金额总和。具体调度如下图。

可以发现,这样的调度就不满足事务的一致性。原因在于:
- T1 过早的释放了数据B的锁。这导致 T2 误以为自己已经获得了所有需要的数据,就开始执行。但 T2 读取的A并不是 T1 更新后的值。
因此我们还需要:基于锁的协议(Lock-Based Protocols)来对申请和释放锁进行规定。(所谓协议,就是一些需遵守的规则罢了)
所以,针对上面例子,我们可以规定:释放锁被推迟到事务结束时。这样就能确保调度时可序列化的。
Unlocking is delayed to the end of the transaction.
死锁
当我们使用锁时,可能出现以下这种情况:
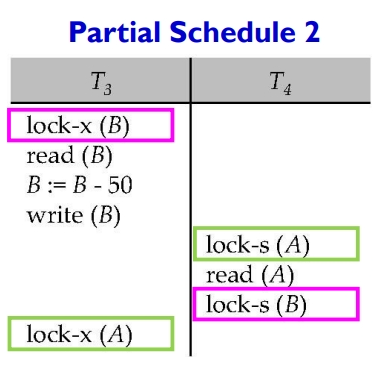
T3 和 T4 都需要数据 A、B。但 T3 持有B并给B上锁;T4 持有A并给A上锁。此时,T3 和 T4 都有彼此想要的数据项,但又都不愿意释放出自己手中的数据。于是调度就僵持在这里,无法进行。这种情况,我们称之为:死锁(deadlock)。
就像《剪刀手爱德华》里说的:“如果我没有刀,我无法保护你;如果我拿着刀,我无法拥抱你。”如果不采用锁,无法保证事务的一致性;但如果采用锁,又会产生死锁的情况。
“两害相权取其轻”。相较于数据的不一致,死锁是可以接受的。 处理死锁的思路一般有两种:
- 预防:采用 deadlock prevention protocol,保证系统永远不会进入死锁状态。
- 修复:允许系统进入死锁状态,进入后进行恢复就好。
当系统有很高频率进入死锁状态时,“预防”是更好的选择。否则“进入后再恢复”是更高效的方案。
死锁预防(deadlock prevention)有以下两种常见方式:
- 一个事务在执行的开始就把所有需要的数据上锁。要么一次性锁住所有需要的数据,要么一个也不锁。
- 系统给所有资源分配一个全局的顺序号,事务必须按顺序请求资源。也就是说:如果一个事务已经持有了一个资源,它只能请求顺序号更大的资源,不能请求顺序号更小的资源。但如果一个事务需要请求顺序号更小的资源,它必须:1. 释放当前持有的所有锁;2. 按照顺序从小到大重新申请所有所需的资源。
第一种策略易于实现,但缺点明显:在事务的开始时,系统难以预测它究竟需要哪些数据;其次这样的数据利用效率非常低。
第二种策略可能不那么易于理解,我们举一个例子:
假设有三个资源 A、B 和 C,它们的顺序号分别是 1、2 和 3。
- 事务 T1 需要锁定资源 B 和 A。
- 事务 T2 需要锁定资源 A 和 B。
此时事务 T1 已经锁定资源 B,事务 T2 已经锁定资源 A。但由于 资源A顺序 < 资源B顺序 ,事务 T1 不能锁定 A,所以它会释放资源 B,重新请求上锁,这样事务 T2 就能顺利获得资源 B,从而避免死锁。
这种策略的优势在于:易于实现,不需要对底层的并发控制系统进行修改。
死锁恢复一般采用抢占和回滚(preemption and transaction rollbacks):其实就是,抢走一个事务手中的锁,并将这些锁给其他事务,并将被抢的事务回滚。但是谁抢走谁呢?这就需要一个判断标准:事务的时间戳(Transaction timestamps)。
形象地比喻就是“银行办理业务”:每个人都会到大厅机器上取一个号码,这个就是你的时间戳。大家根据时间戳先后决定谁先办理业务。
在数据库中也是相似的,一般有两种策略:
- Wait-Die Scheme(new-die & old-wait):如果一个较老的事务请求一个被较新的事务持有的资源,那么较老的事务会等待。如果一个较新的事务请求一个被较老的事务持有的资源,那么较新的事务会被回滚。
- Wound-Wait Scheme(new-wait & old-die):如果果一个较老的事务请求一个被较新的事务持有的资源,那么较新的事务会被立即回滚。如果一个较新的事务请求一个被较老的事务持有的资源,那么较新的事务会等待。
举例说明一下:
- 事务 T14、T15 和 T16 的时间戳分别为 5、10 和 15。
- 在 Wait-Die 方案下:如果 T14 请求一个由 T15 持有的数据项,那么 T14 将会等待。如果 T16 请求一个由 T15 持有的数据项,那么 T16 将会被回滚。
- 在 Wound-Wait 方案下:如果 T14 请求一个由 T15 持有的数据项,那么数据项将从 T15 中被抢占,T15 将会被回滚。如果 T16 请求一个由 T15 持有的数据项,那么 T16 将会等待。
但这两种策略都会带来不必要的回滚。
还有一种解决死锁的方式:锁超时(lock-timeout):申请锁的事务最多等待一定时间,如果没有得到锁,则该事务自动回滚,并重启。
这种方式介于预防和恢复之间。但超时的时间限制(timeout interval)是不好把握的。太长,死锁卡住的时间就久;太短,一个事务太没耐心,从而可能不停回滚。
饿死
当我们使用锁时,会出现以下这种情况:
- 一个事务可能在等待某个数据的排他锁,同时,许多其他事务请求并获得了该项目上的S锁(共享锁)。
形象的比喻就是“银行业务办理窗口”:
- 事务比作人,数据比作窗口,若干事务正在排队访问数据。你前面有一个人正在读数据,但你是想写数据,你只能等待。这这时后面的人说:“嘿,我就读数据,让我凑过去看一眼”,于是他插队到你前面(获得了共享锁)。后面所有想读数据的人,都能这样插队到你前面。即使最开始的读数据的人已经完成离开了,但还有新的人正在读数据。如此,你就一直无法获取到写数据的排他锁。
这种情况,我们称之为:饿死(Starvation)。
避免这样的“插队”问题,也是很简单的——遵守“先来后到”的规则就好。具体如下。
当事务T请求数据Q的M型锁时,并发控制管理器授权加锁的条件是:
- 此时,数据Q上没有与M不兼容的锁
- 此时,不存在 “正在等待加锁的” 且 “排队在事务T之前的” 的事务。
二相锁协议
在 two-phase locking protocol 中:释放锁不必须在事务结束时进行。
二相锁协议是能保证调度可序列化的。它要求每个事务分两个阶段提出加锁、解锁的申请:
- growing phase:事务只能获得锁。
- shrinking phase:事务只能释放锁。
例如下图中:T1 和 T2 就不是二相锁,T3 和 T4 就是二相锁。(且将unlock(B)提前到lock-X(A)后面执行,也仍是遵守协议的)

对于任何事务,它获得它的最后一个锁的时候,也就是增长阶段结束的时候,我们称之为:事务的封锁点(lock point)。
二相锁是可序列化的,且:各个事务实际上就是按照 lock point 的先后进行顺序执行完成的。
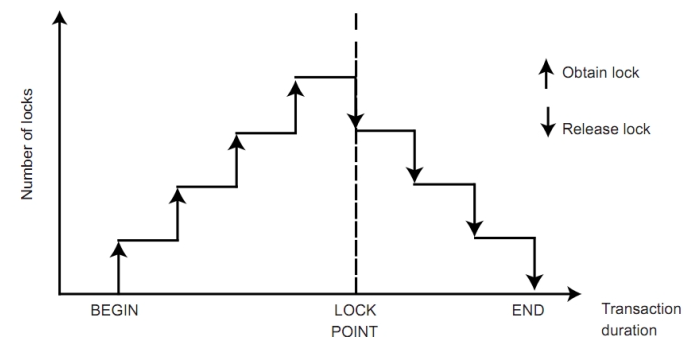
但二相锁并不是完美的:
- 二相锁不能避免死锁的问题。
- 二项锁不是无级联的。它仍然可能出现级联回滚(cascading roll back)的情况。
为了避免级联回滚,我们可以提出更严格的二相锁协议:
- Strict two-phase locking protocol:一个事务必须持有 所有的排他锁 直到它提交或中止。
- Rigorous two-phase locking protocol:一个事务必须持有 所有锁 直到它提交或中止。
其中后者的序列化的顺序是按照事务的提交时间(而不再是lock point)。
锁的转换
共享锁和排他锁时可以相互转换的,通过升级(upgrading)和降级(downgrading)。
例如:当事务T已经拥有S锁,且又需要X锁时:它可以将S锁升级成X锁。

但锁的升级和降级不是能乱来的:
- 升级只能发生在 growing phase
- 降级只能发生在 shrinking phase
且进行锁转换时也需要注意:是否与当前已有的锁兼容。若不兼容,则需要等待。
所以,当一个事务需要锁时,并不是直接申请,而是先检查是否已有锁。若有,则请求升级或者降级;若无,再申请加锁。
大部分数据库都采用 Strict two-phase locking protocol 和 lock conversion 的机制。
锁管理器
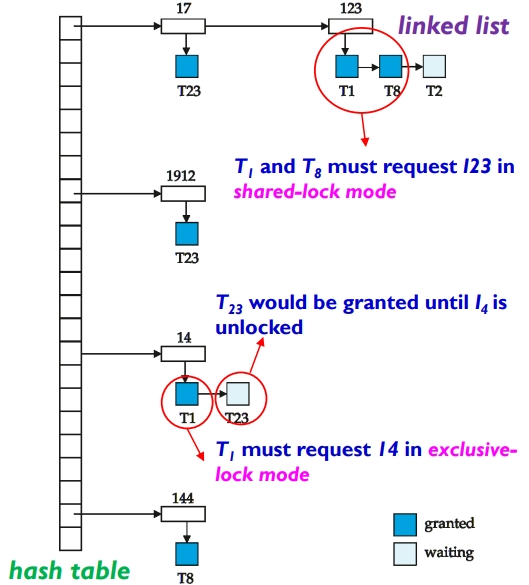
锁管理器(lock manager)就是一个进程,并维护一个记录已有锁和等待锁的数据结构——锁表(lock table)。各个事务向其发送加锁、解锁的请求。
锁表结构如下图所示:
- 用哈希链表存储各个数据项17、123、1912、14、144
- 某一个数据项上的锁,存储在指向当前数据项的链表中。第一个是被授权的锁,后续的是正在等待的锁。
- 例如:T2 申请 “数据123” 上的排他锁,此时 T1 和 T8 已持有其共享锁。那么 T2 的申请会被添加到 “数据123” 的链表的末尾。
- 如果一个事务终止(aborted),锁管理器会释放该事务持有的所有锁。
多粒度
截至目前,我们讨论的并发控制都是以一个个数据为单位,但实际情况中,一个事务可能请求访问整个数据库的内容,这时一个个数据的上锁会非常耽误时间,我们希望能直接一次请求就能锁住整个数据库。所以,我们需要根据各种数据项大小,定义数据粒度的层次。
多粒度机制(Multiple granularity mechanism)允许数据项具有不同的大小,并定义一个数据粒度的层次结构,其中较小的粒度嵌套在较大的粒度之内。这样的层次结构可以用树状图形来表示。树中的每个节点都可以单独加锁。当一个事务显式地锁定树中的一个节点时,它隐式地以相同的模式锁定该节点的所有子孙节点。
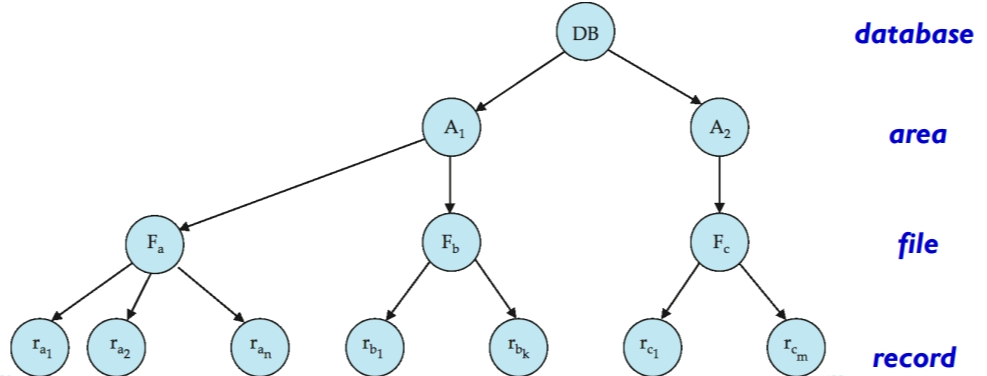
但是,每一次加锁,都需要判定当前节点是否能加锁。例如:事务 T1 想给 A1 加共享锁,但是系统必须检查 A1 的所有子节点中是否有排他锁。若有,则不能加锁。但如果每次加锁都需要搜索整个树,就违背了多粒度机制的初衷——快速地给大量数据加锁。
所以我们引入了一种新的锁的模式:意向锁(intention lock mode)。
意向锁
意向锁也是可能出现死锁的。
意向锁有五种锁的模式:
- S(共享锁)
- X(排他锁)
- IS(共享意向锁):表明将要在更低层次加共享锁。
- IX(排他意向锁):表明将要在更低层次加排他锁。
- SIX(共享排他意向锁):表明在更高层次加了共享锁,并且将要在更低层次加独占锁。(SIX = S + IX)
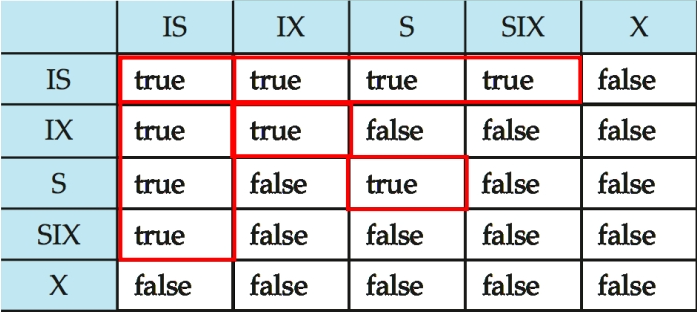
核心想法就是:增加 IS、IX、SIX 模式,来反映子节点的上锁情况。这样给当前节点上锁时,就不必搜索当前节点的子树,检查当前节点的锁就能知道其子节点的上锁情况。当我们给一个节点上意向锁时,我们只需要更新当前节点和其父节点的锁即可,不需要更改其子节点的锁。
事务 Ti 可以使用以下规则锁定节点 Q:
- 必须遵守上图种的锁兼容矩阵。
- 必须首先锁定树的根节点,并且可以以任何模式锁定。
- 事务 Ti 只有在 Q 的父节点被 Ti 以 IX 或 IS 模式锁定时,才能以 S 或 IS 模式锁定节点 Q。
- 事务 Ti 只有在 Q 的父节点被 Ti 以 IX 或 SIX 模式锁定时,才能以 X、SIX 或 IX 模式锁定节点 Q。
- 事务 Ti 只有在之前没有解锁过任何节点的情况下才能锁定节点(即:Ti 遵循二相锁协议)。
- 事务 Ti 只有在 Q 的子节点都没有被 Ti 锁定的情况下才能解锁节点 Q。
请注意:锁定是从根到叶节点的顺序进行的,而解锁是从叶到根的顺序进行的。
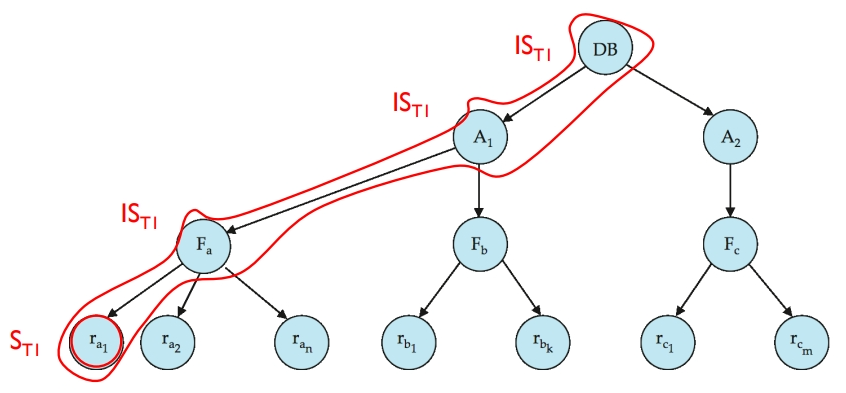
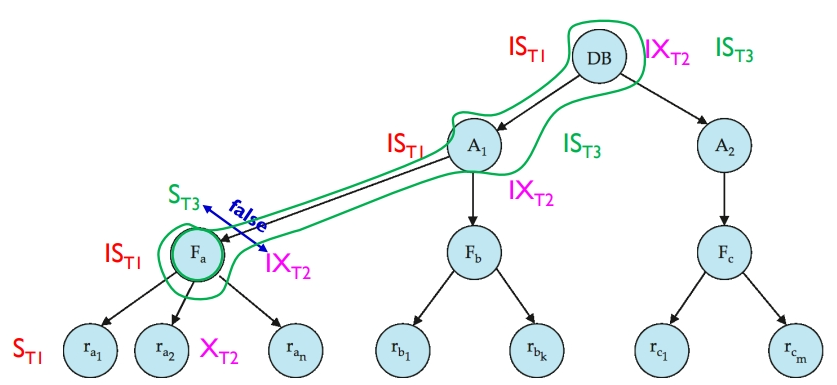
举例说明一下,假设依次发生以下请求:
事务 T1 读取记录 ra1 。
事务 T2 更新记录 ra2 。
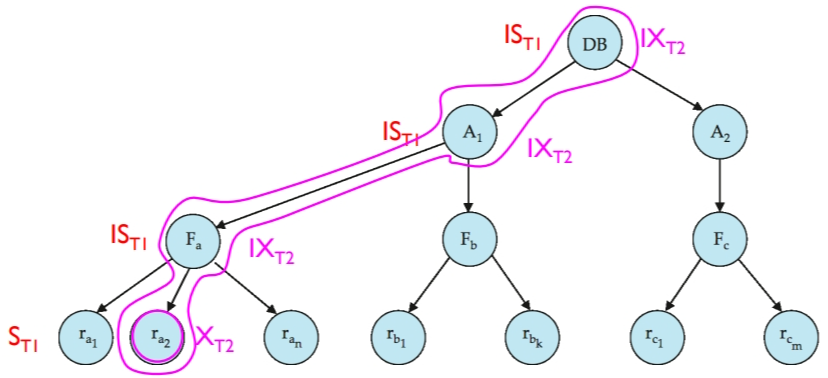
事务 T3 读取文件 Fa 。(但此时 ST3 锁和 IXT2 锁相矛盾了,所以 T3 会进行等待)
时间戳
之前基于锁的各种协议,最终可序列化的顺序都是由上锁的时刻决定。现在我们介绍第二种实现并行控制的方法:基于时间戳的协议(Timestamp-Based Protocols)。这种方法的事务可序列化顺序是预先决定的。
事务时间戳
每个事务 Ti 都会被分配一个唯一的固定时间戳 TS(Ti)。这个时间戳在事务 Ti 开始执行之前由数据库系统分配。
如果事务 Ti 被分配了时间戳 TS(Ti),并且有一个新的事务 Tj 进入系统,那么 TS(Ti) < TS(Tj)。
有两种简单的方法来实现时间戳方案:
使用系统时钟的值作为时间戳——事务的时间戳等于事务进入系统时的时钟值。
使用逻辑计数器,该计数器在分配新时间戳后递增——事务的时间戳等于事务进入系统时计数器的值。
时间戳决定了可串行化的顺序。
- 如果 TS(Ti) < TS(Tj),则生成度必须等效于一个串行调度,其中 Ti 出现在事务 Tj 之前。
数据时间戳
为了实现这个方案,协议为每个数据项 Q 维护两个时间戳值:
- **W-timestamp(Q)**:成功执行写操作 write(Q) 的任意事务的最大时间戳。
- **R-timestamp(Q)**:成功执行读操作 read(Q) 的任意事务的最大时间戳。
当新的指令(read(Q) 或 write(Q))执行时,时间戳会被更新。
时间戳协议
时间戳排序协议确保:任何冲突的读写操作按照时间戳顺序执行。
假设事务 Ti 执行一个读操作 read(Q):
如果 TS(Ti) < W-timestamp(Q),那么 Ti 需要读取一个已被后续事务覆盖的数据值。因此,读操作会被拒绝,并且 Ti 将被回滚。
如果 TS(Ti) ≥ W-timestamp(Q),则读操作会被执行,并且 R-timestamp(Q) 被设置为 R-timestamp(Q) 和 TS(Ti) 中的最大值。
假设事务 执行一个写操作 write(Q):
如果 TS(Ti) < R-timestamp(Q),则表示 Ti 正想写一个已经被后续事务读取了的数据 Q 的值,但系统认为这个值不会再被产生。因此,写操作会被拒绝,并且 Ti 将被回滚。
如果 TS(Ti) < W-timestamp(Q),则表示 Ti 尝试写入一个已经过时的 Q 的值。因此,这个写操作也会被拒绝,并且 Ti 将被回滚。
否则,写操作会被执行,并且设置 W-timestamp(Q) = TS(Ti)。
请注意:如果一个事务被回滚了,系统会重新给它分配一个时间戳,并重启它。
时间戳协议保证了所有事务按照时间戳的顺序执行完成。所以,在时间戳协议里,不会出现死锁。但是仍然可能出现饿死的情况:一系列短事务可能会不断的被重启,因为一些长事务一直在执行。

时间戳协议虽然避免了死锁的问题,但它不能避免级联,而且很可能不是可恢复的。
举例说明一下。假设事务 Ti 中止(abort),但是事务 Tj 已经读取了由 Ti 写入的数据项:
- 那么事务 Tj 必须中止(abort)。如果允许 Tj 先提交,那么该调度就不是可恢复的。
- 此外,任何已经读取了由 Tj 写入的数据项的事务都必须中止(abort)。
- 这可能导致级联回滚,即一系列的事务被迫回滚。
这个问题的核心在于:当数据项 Q 在“被事务 Tj 写后”和“事务 Tj 提交”之间的时间里,数据项 Q 并不是盖棺定论的,可能因事务 Tj 的回滚而改变,但数据项 Q 又可能被其他事务读取。所以解决方法的核心也就是:让所有事务都等到数据盖棺定论的时候再读取。
常见解决方法有以下三种:
- 在事务结束时一次性执行所有写操作。
- 延迟读取未提交数据项,直到更新该数据项的事务已提交为止。
- 跟踪未提交的写操作,只允许事务 Ti 在读取的值都是由已提交事务写入后才能提交(即提交依赖)。
Thomas 写规则
在时间戳协议的基础上,我们可以进一步增强数据库系统的并行能力。
考虑下图中的例子:事务 T27 因为 write(Q) 操作被迫回滚。但实际上,按照“事务 T27 先执行,事务 T28 后执行”的顺序,事务 T27 的 write(Q) 操作实际上会被事务 T28 的 write(Q) 操作覆盖掉。也就是说:事务 T27 的 write(Q) 操作根本没必要执行,事务 T27 也不必回滚。
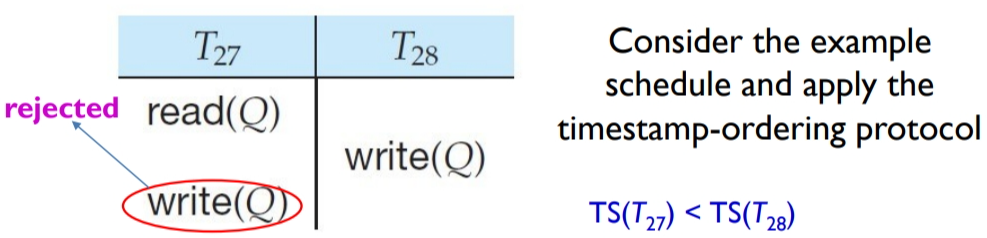
对于过时的写操作,我们进行忽略。于是有了 Thomas’ Write Rule。
假设事务 Ti 发出写操作 write(Q)。
- 如果 TS(Ti) < R-timestamp(Q):则表示 Ti 正在更新一个已经被后续事务读取了的 Q,而系统曾假定这个值不会再被产生。因此,系统拒绝写操作,并回滚事务 Ti。(与原协议相同)
- 如果 TS(Ti) < W-timestamp(Q):则表示 Ti 尝试写入一个过时的 Q 的值。根据修改后的规则,这个写操作可以被忽略。(新规则)
- 否则:系统执行写操作,并将 W-timestamp(Q) 设置为 TS(Ti)。(与原协议相同)
(视图)可序列化
通过忽略过时的写操作,Thomas 的写入规则允许产生:不符合冲突可串行化但是正确的调度。这就促使我们定义一种新的可序列化:视图可串行化。
如果两个调度 S 和 S’ 包含相同的一组事务,并且满足以下三个条件,那么它们被称为视图等价。
第1、2条件保证了相同的值和计算。第2、3个条件保证了相同的最终状态。
- 对于每个数据项 Q,如果事务 Ti 在调度 S 中读取了 Q 的初始值,则在调度 S’ 中,事务 Ti 也必须读取 Q 的初始值。(确保读取相同的初始值)
- 对于每个数据项 Q,如果事务 Ti 在调度 S 中执行了 read(Q) 操作,并且这个值是由事务 Tj 执行的 write(Q) 操作产生的,则在调度 S’ 中,事务 Ti 也必须读取到由同一个事务 Tj 执行的 write(Q) 操作产生的值。(确保读取由同一事务写入的值)
- 对于每个数据项 Q,在调度 S 中执行最终的 write(Q) 操作的事务(如果有的话),在调度 S’ 中也必须执行最终的 write(Q) 操作。(确保执行相同的最终写操作)
如果它与某个串行调度视图等价,调度 S 是视图可串行化(View Serializable)的。
