引言
在数据库中,join 是经常使用的操作,但其工作量也可能是很大的。那么如何高效地完成 join 操作呢?
这篇 blog 将介绍:
- 常见的 join 实现方式
- 如何在 Postgresql 源代码中实现 block nested loop join
常见 join 算法
Simple Nested-Loop Join
简单来说,Simple Nested-Loop Join 就是一个双层 for 循环 ,通过循环外层表的行数据,逐个与内层表的所有行数据进行比较来获取结果。
用伪代码描述大致如下:
1 | for (each tuple i in outer relation) { |
特点:
Nested-Loop Join 简单粗暴容易理解,就是通过双层循环比较数据来获得结果,但是这种算法显然太过于粗鲁,如果每个表有1万条数据,那么对数据比较的次数=1万 * 1万 = 1亿次,很显然这种查询效率会非常慢。
当然,数据库肯定不会这么粗暴地 join,所以就出现了后面的两种对Nested-Loop Join 优化算法。在执行 join 查询时,数据库会根据情况选择后面的两种 join 优化算法的进行join查询。
Index Nested-Loop Join
Index Nested-Loop Join 的优化思路主要是:减少内层表数据的匹配次数。
简单来说,Index Nested-Loop Join 就是通过外层表匹配条件,直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较,这样极大的减少了对内层表的匹配次数,从原来的 “匹配次数=外层表行数 * 内层表行数”,变成了 “外层表的行数 * 内层表索引的高度”,极大的提升了 join 的性能。
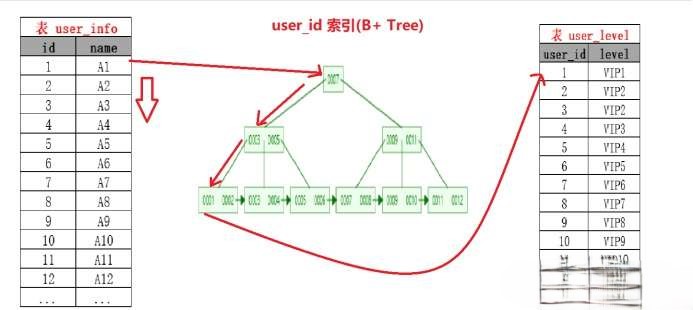
但是,Index Nested-Loop Join 算法的前提是:匹配的字段必须建立了索引。
Block Nested-Loop join
Block Nested-Loop Join 其优化思路是:减少内层表的扫表次数。
Block Nested-Loop Join 算法意在通过一次性缓存外层表的多条数据,以此来减少内层表的扫表次数,从而达到提升性能的目的。
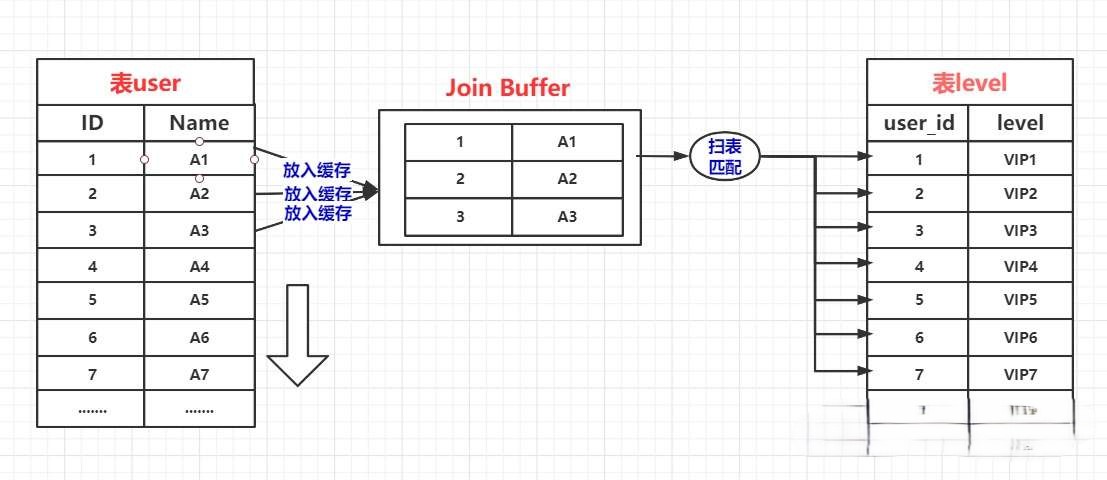
如果无法使用 Index Nested-Loop Join 时候,一般都会使用 Block Nested-Loop Join 算法。
PostgreSQL 实验
准备工作
下载 postgresql 源代码:
在本地编译并安装 postgresql:
1
2
3
4
5
6
7
8
9
10
11# 切换到源代码目录
cd postgresql-12.0
# 初始化 make 配置
/configure --enable-depend --enable-cassert --enable-debug CFLAGS="-O0" --prefix=$HOME/pgsql
# 编译
make
# 安装(一般会安装到$HOME/pgsql)
make install初始化本地 postgresql 服务器:
若你不幸把 pgsql 装到别的位置,把
$HOME/pgsql替换成你安装的路径。1
$HOME/pgsql/bin/initdb -D $HOME/pgsql/data --locale=C
启动 postgresql 服务器:
1
/home/[guanz]/pgsql/bin/pg_ctl -D /home/[guanz]/pgsql/data -l logfile start
连接 postgresql 服务器:
1
$HOME/pgsql/bin/psql postgres
关闭 postgresql 服务器:
“Ctrl + D” 和
\q均可以退出 postgresql 命令行。1
2# This command depends on your installation location, please modify it
/home/[guanz]/pgsql/bin/pg_ctl -D /home/[guanz]/pgsql/data stop加载测试数据:
1
2
3postgres=# CREATE DATABASE similarity;
postgres-# \c similarity
postgres-# \i /home/[guanz/data/]similarity_data.sql
源代码解读
虽然源代码很多,但我们只关注以下几个文件:
- src/backend/executor/nodeNestloop.c
- src/include/executor/nodeNestloop.h
- src/include/nodes/execnodes.h
Nested-Loop 主要算法都在 nodeNestloop.c 中实现:
其中 ExecNestLoop() 是执行嵌套循环连接,其余两个 ExecInitNestLoop() 和 ExecEndNestLoop() 则分别完成初始化和终止。
1 | /* |
源代码修改
我们主要做了一下修改:
- 新增了结构体类型 NestedBlock ,用于存放中间缓存的外部元组。
与之相应地:
- 增加了 GetNestedBlock() 函数,用于获取新的中间元组。
- 在上下文类型 ExprContext 中增加 NestedBlock 变量,将中间缓存元组记录在上下文中。
- 修改 ExecNestLoop() 函数:外部元组一次取出至多 NESTED_BLOCK_SIZE 个元组放入缓存 NestedBlock 中,并照旧扫描内部元组。但每次需要将缓存中的所有 outer tuple 一一与 inner tuple 进行比较,且外部元组的指针需要往后移动 NESTED_BLOCK_SIZE 个元组。
修改细节如下(修改之处都加有 xht03 注释):
execnodes.h
1 | // xht03 |
nodeNestloop.h
1 |
|
nodeNestloop.c
1 | // xht03 |
源代码测试
重新编译并安装 postgresql 后,设置 NESTED_BLOCK_SIZE = 1、2、8、64、128、1024,运行下面语句两次,取第二次运行时间。
在数据库命令行中输入:
\timing,打开测时间功能。
1 | SELECT count(*) FROM restaurantaddress ra, restaurantphone rp WHERE ra.name = rp.name; |
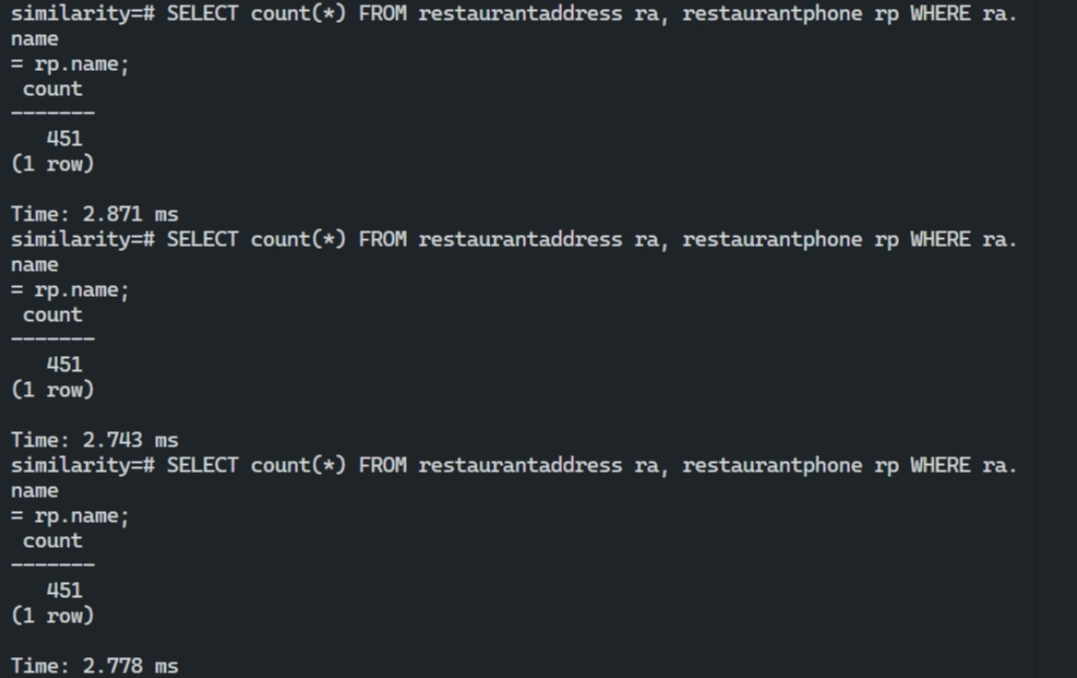
| NESTED_BLOCK_SIZE | 时间1/ms | 时间2/ms | 时间3/ms |
|---|---|---|---|
| 1 | 2.710 | 2.559 | 2.565 |
| 2 | 2.579 | 2.753 | 2.636 |
| 8 | 2.337 | 2.483 | 2.716 |
| 64 | 2.277 | 2.441 | 1.896 |
| 128 | 2.657 | 2.543 | 2.464 |
| 1024 | 2.871 | 2.743 | 2.778 |
这样的实验结果是符合预期的:
- NESTED_BLOCK_SIZE 太小时,与 Simple Nested-Loop 相近;当 NESTED_BLOCK_SIZE 太大时,就相当于内外表互换后的 Simple Nested-Loop。所以当 NESTED_BLOCK_SIZE 取一个大小适中的值时,Block Nested-Loop 才能性能最大化。