二叉搜索树
二叉搜索树
二叉搜索树(Binary Search Tree,BST)是一种特殊的二叉树,它具有以下性质:
有序性:对于树中的任意节点,其左子树上所有节点的值都小于该节点的值,其右子树上所有节点的值都大于该节点的值。
二叉树结构:每个节点最多有两个子节点,即左子节点和右子节点。
没有键值重复:树中不存在两个节点具有相同的键值。
二叉搜索树的基本操作包括:
- 查找(Search):给定一个值,查找树中是否存在该值。
- 插入(Insert):插入一个新的值。
- 删除(Delete):删除树中的一个节点。
- 遍历(Walk):二叉搜索树可以通过中序遍历得到一个有序的元素序列。
二叉搜索树上的基本操作所花费的时间与这棵树的高度 h 成正比。
遍历操作
二叉搜索树性质允许我们通过一个简单的递归算法来按序输出二叉搜索树中的所有关键字,这种算法称为中序遍历(inorder tree walk)算法。
这样命名的原因是输出的子树根的关键字位于其左子树的关键字值和右子树的关键字值之间。(前序遍历、后序遍历类似。)
伪代码如下:
1 | INORDER-TREE-WALK(x) |
显然,遍历一个二叉搜索树的时间代价是 **Θ(n)**。
查询操作
在一棵高度为h 的二叉搜索树上,查询操作
SEARCH、MINIMUM、MAXIMUM、SUCCESSOR和PREDECESSOR均可以在 O(h) 时间内完成。
查找
我们通过 TREE-SEARCH(x, k),查找以x为根的树中是否包含关键字 k。
1 | TREE-SEARCH(x, k) |
不难证明,查找操作的时间代价是 **O(h)**。
最小值和最大值
TREE-MINIMUM(x)寻找以x为根的树中的最小值(就是子树的最左节点)。
1 | TREE-MINIMUM(x) |
TREE-MAXIMUM(x)寻找以x为根的树中的最大值(就是子树的最右节点)。
1 | TREE-MAXIMUM(x) |
这两个过程在一棵高度为 h 的树上均能在 O(h) 时间内执行完。
后继和前驱
所谓后继,就是当前节点在中序遍历过程中的下一个节点。这也是从小到大排序中,大于当前节点的最小节点。
前驱同理。
1 | # python 实现 |
1 | # python 实现 |
该过程或者遵从一条简单路径沿树向上或者遵从简单路径沿树向下。所以,SUCCESSOR 操作可以在 O(h) 时间内完成。
插入操作
插入操作,与查找操作类似,只不过是在二叉搜索树中没能找到对应元素。此时,我们就在查找路径的尽头,插入新元素。
所以,TREE-INSERT 操作可以在 O(h) 时间内完成。
伪代码如下:
1 | TREE-INSERT(T, z) |
删除操作
删除的过程如下:
- 如果被删除节点 z 没有孩子,则直接删除 z。
- 如果 z 只有一个孩子,那么 z 孩子替代 z 的位置。
- 如果 z 有两个孩子:
- z 的后继 y(一定在 z 的右子树中)替代 z 的位置。
- y 的孩子代替 y 的位置。(y 是子树中的最左节点,只有一个孩子。)
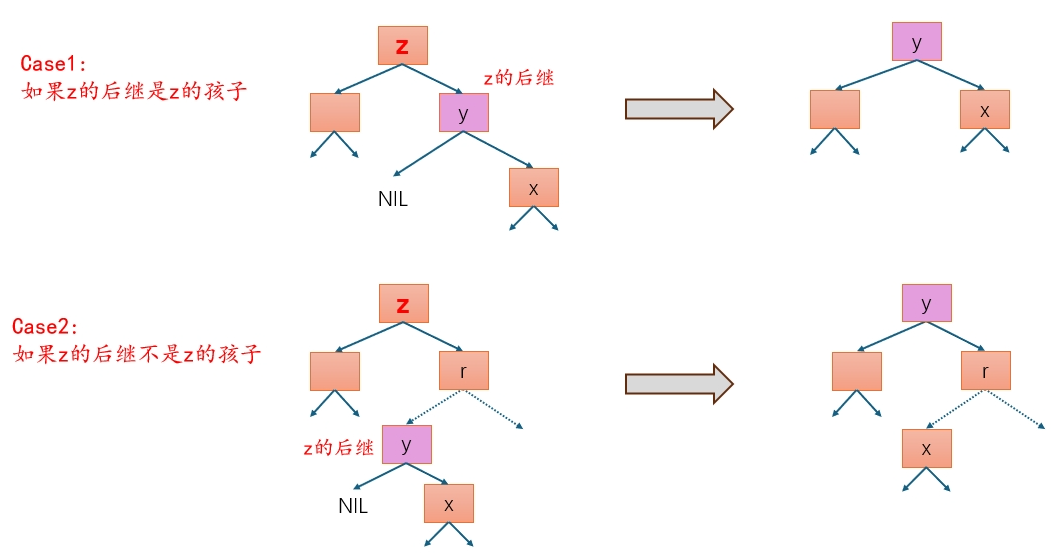
不难证明,TREE-DELETE 能在 O(h) 时间内完成。
随机构建
随机构建二叉搜索树是指:按随机次序插入关键字到一棵初始的空树中而生成的树,且输入的关键字排列等可能的出现。
一棵有 n 个不同关键字的随机构建二叉搜索树的期望高度为 **O(lgn)**。
证明:
红黑树
红黑树
红黑树是满足下面红黑性质的二叉搜索树:
- 每个结点或是红色的,或是黑色的。
- 根结点是黑色的。
- 每个叶结点(NIL) 是黑色的。
- 如果一个结点是红色的,则它的两个子结点都是黑色的。
- 对每个结点,从该结点到其所有后代叶结点的简单路径上,均包含相同数目的黑色结点。
图片例子
一棵有 n 个内部结点的红黑树的高度至多为 **2·lg(n+1)**。
proof
查询操作
由此可知:**红黑树的高度是 O(lgn)**。再结合二叉搜索树的性质,我们可知:红黑树的查询操作(SEARCH、MINMUN、MAXIMUM、SUCESSOR)均是 **O(lgn)**。
旋转操作
图片
插入操作
插入新节点:使用二叉搜索树的
TREE_INSERT方法插入新节点,并将其颜色设为红色(可能会违反性质4,还需调整)。调整树以恢复红黑性质:检查父节点颜色。
如果新节点的父节点是黑色的,则树仍然是平衡的,不需要调整。
如果父节点是红色,则需要进一步检查叔叔节点:
如果新节点的叔叔节点存在且为红色:
将父节点和叔叔节点都涂成黑色,并将祖父节点涂成红色,然后从祖父节点重新开始调整过程(递归调用)。
如果叔叔节点是黑色或为空:
根据新节点和父节点相对于祖父节点的位置,进行以下旋转之一:
- 左左情况(LL):新节点是其父节点的左孩子,且父节点是祖父节点的左孩子。进行右旋转,然后交换祖父节点和父节点的颜色。
- 右右情况(RR):新节点是其父节点的右孩子,且父节点是祖父节点的右孩子。进行左旋转,然后交换祖父节点和父节点的颜色。
- 左右情况(LR):新节点是其父节点的左孩子,但父节点是祖父节点的右孩子。首先对父节点进行左旋转,将新节点变为左左情况,然后进行右旋转并交换颜色。
- 右左情况(RL):新节点是其父节点的右孩子,但父节点是祖父节点的左孩子。首先对父节点进行右旋转,将新节点变为右右情况,然后进行左旋转并交换颜色。
根节点颜色调整:如果新节点成为根节点(即原根节点是红色),则将其颜色改为黑色,以满足根节点必须是黑色的性质。
递归结束条件:当新节点变为黑色或成为根节点时,算法结束。
旋转图片 P182
删除操作
散列表
散列表
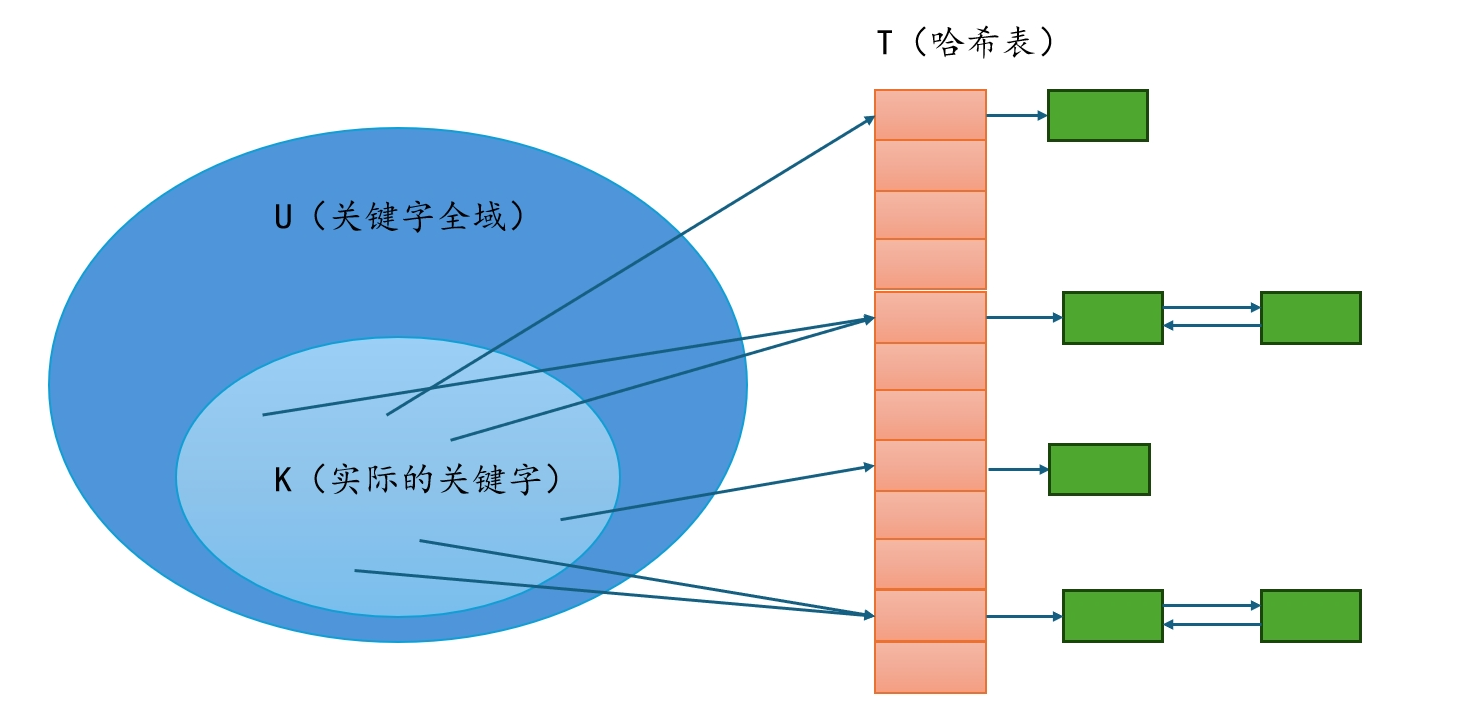
散列表(Hash Table),也称为哈希表,是一种通过哈希函数将键(Key)映射到表中一个位置以便快速访问记录的数据结构。它的主要目的是提供快速的数据插入、删除和查找操作。散列表通常由数组支持,这个数组称为“槽”或“桶”,数组的每个位置对应一个可能的哈希值。
大量键值对存储时:
- 如果使用数组,并使用键作为索引,则当键的取值范围很广,但键值对数量却不多时:需要开辟很大的数组空间,却只有很少数空间被使用,造成空间浪费。
- 所以,我们希望通过hash function将原本稀疏散落在数组各处的键值对,通过函数映射,集中存放在一个更小的空间中,提高空间利用率。
散列表的基本操作包括:
- 插入(Insert):将一个新的键值对插入到散列表中。
- 查找(Search):通过给定的键快速找到对应的值。
- 删除(Delete):从散列表中删除一个键值对。
散列表的工作原理如下:
- 哈希函数(Hash Function):选择一个合适的哈希函数,它能够将输入的键(可以是任意数据类型)转换为数组索引。一个好的哈希函数应该能够均匀地将键分布在数组的索引上,以减少冲突。
- 冲突解决(Collision Resolution):由于不同的键可能会映射到同一个索引上,这种情况称为冲突。解决冲突的方法有:
- 链地址法(Chaining):每个数组索引处都有一个链表,所有映射到该索引的键值对都存储在这个链表中。
- 开放寻址法(Open Addressing):如果发生冲突,寻找表中的另一个空闲位置来存储该键值对。常见的开放寻址策略有线性探测、二次探测和双重散列。
冲突解决
链地址法
在链地址法(chaining)中,每个数组索引(或称为“槽”或“桶”)都关联一个链表,所有映射到该索引的元素都会被存储在这个链表中。
链地址法的插入、查找、删除操作的伪代码如下:
1 | CHAINED-HASH-INSERT(T ,x) |
给定一个能存放 n 个元素的、具有 m 个槽位的散列表 T。定义 T 的装载因子(load factor) α 为n/m,即:一个链的平均存储元素数。
插入操作:将新的元素链接到对应链表的头部,用时**O(1)**。
删除操作:**如果是双向链表,用时O(1)**。如果是单向链表,用时与搜索操作时间相近。
注意,这里删除操作
CHAINED-HASH-DELETE(T,x)以元素 x 而不是它的关键字 k 作为输入,所以无需先搜索 x。搜索操作:
在简单均匀散列的假设下,对于用链接法解决冲突的散列表,一次不成功查找的平均时间为 Θ(1 + α) 。
证明:如果查找的关键字 k 不在哈希表中,则需要首先找到对应槽的链表,再遍历整个链表,确定关键字 k 不在哈希表中。而链表的长度期望是 α 。所以总用时是:Θ(1 + α) 。
在简单均匀散列的假设下,对于用链接法解决冲突的散列表,一次成功查找所需的平均时间为 Θ(1 + α) 。
证明:如果查找的关键字 k 在哈希表中,则需要先找到对应槽的链表,再搜索该链表。链表期望长度是 α ,关键字 k 等可能地出现在链表第1、2、……、α 个位置。所以总用时是:Θ(1 + (1+α)/2) = Θ(1 + α) 。
综上,当n、m数量级相近时,即n=O(m)时:链地址法的所有字典操作均是 O(1) 时间。
python代码实现大致如下:
1 | # 双向链表 |
开放寻址法
在开放寻址法(open addressing) 中,所有的元素都存放在散列表里。这里既没有链表,也没有元素存放在散列表外。因此在开放寻址法中,散列表可能会被填满,且装载因子 α 不超过1。
插入操作
两个不同的键被哈希函数映射到同一个索引时,开放寻址法会再寻找新的空位索引,直至找到,再存放新插入的键值对。
插入操作伪代码如下:
HASH-INSERT(T,x)将元素 x 插入到哈希表 T 中。如果第一次 hash 后的位置冲突了,则会再做第2、3……次 hash,直至找到空位用以插入新元素。所以**开放寻址法的 hash 函数需要两个参数:关键字 k 和第几次 i **。
1 | HASH-INSERT(T,x) |
常见探查方法,也即是对应的哈希函数有:
线性探查:
当发生冲突时,通过按顺序查找下一个空闲位置来存储键值对。
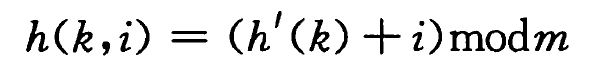
线性探查方法比较容易实现,但它存在着一个问题(群集现象):
当一个空槽前有 i 个满的槽时,该空槽为下一个将被占用的概率是 (i+1)/m。连续被占用的槽就会变得越来越长,因而平均查找时间也会越来越大。
随着连续被占用的槽不断增加,平均查找时间也随之不断增加。
二次探查:
为了减轻线性探查的群集现象,我们每次往后推移二次函数个位置,进行探查。
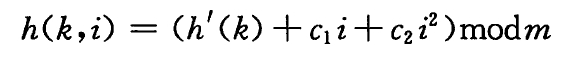
双重散列:
双重散列通过两个不同的哈希函数来计算候选位置。
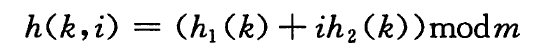
查找操作
查找操作与插入操作类似。
查找操作伪代码如下:
1 | HASH_SEARCH(T,k) |
删除操作
采用开放寻址法时,删除操作是难以实现的。
例如:在插入关键字 k 时,发现槽 i 被占用了,则 k 就被插入到后面的位置上。此时我们欲将槽 i 中的关键字删除,那么就无法检索到关键字 k 了。
所以,删除操作不能直接删除,置为NIL,而是:删除后需要将槽标记为DELETED。
为此,在必须具备删除操作的情形下,一般不采用开放寻址法,而采用链地址法。
算法分析
给定一个装载因子为 α=n/m < 1 的开放寻址散列表,并假设是均匀散列的,则对于一次不成功的查找,其期望的探查次数至多为 1/(1 - α) 。
证明:
对于一个不成功的探查,我们假设经历了 X 次探查。
对于第 i 次探查,如果是空位,则我们知道散列表中没有该关键字,否则还需要继续探查。
现在有 n 个元素和 m 个槽。
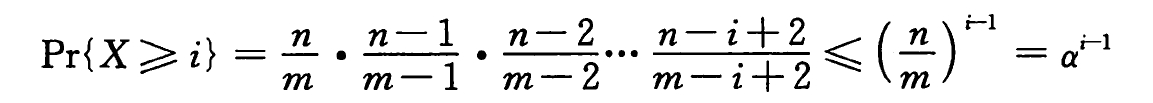
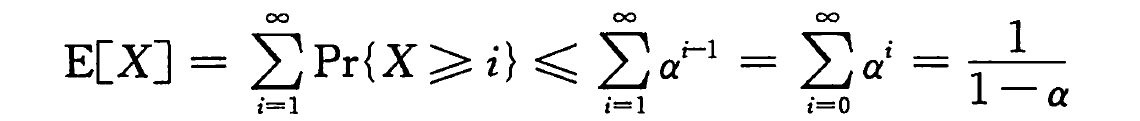
对于一个装载因子为 α < 1 的开放寻址散列表,假设采用均匀散列,且表中的每个关键字被查找的可能性是相同的,一次成功查找中的探查期望数至多为 1/α · ln(1/(1-α)) 。
证明:
查找操作中所遍历的位置序列,与插入该关键字 k 时所遍历的位置序列是相同的。
假设 k 是第 i+1 个插入的关键字,则由上一定理,k 的探查的期望次数至多为 m/(m-i) 。
对散列表中所有 n 个关键字求平均,则得到一次成功查找的探查期望次数为:
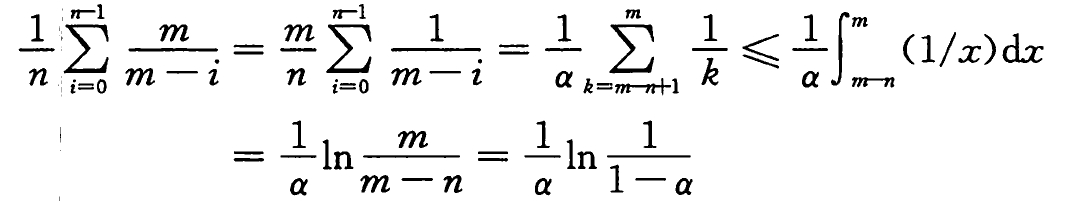
哈希函数
哈希函数将关键字所组成的域到散列表索引所组成的域。
一个好的哈希函数应(近似地)满足简单均匀散列假设:每个关键字都被等可能地散列 m 个槽位中的任何一个,并与其他关键字已散列到哪个槽位无关。
此外,哈希函数的某些情况可能会要求比简单均匀散列更强的性质。例如,可能希望某些很近似的关键字具有截然不同的散列值。
除法散列法
通过取 k 除以 m 的余数,将关键字 k 映射到 m 个槽中的某一个上。
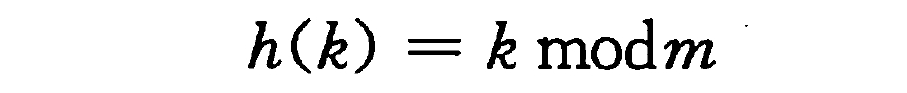
当应用除法散列法时,要避免选择 m 的某些值。例如,m 不应为 2 的幂,因为如果 m=2p,则 h(k) 就是 k 的 p 个最低位数字。
一个不太接近 2 的整数幂的素数,常常是 m 的一个较好的选择。
乘法散列法
乘法散列法分两步:
用关键字 k 乘上常数 A (0<A<1),并提取 kA 的小数部分。
用 m 乘以这个值,再向下取整。
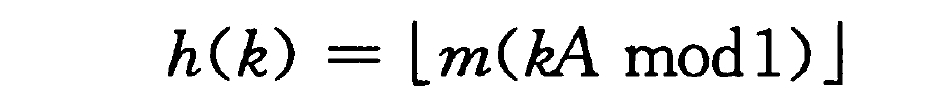
乘法散列法的一个优点是:对 m 的选择不是特别关键,一般选择它为 2 的某个幂次(m=2p, p为某个整数)。这是因为如此在计算机上容易表示。
虽然这个方法对任何的A 值都适用,但对某些值效果更好(如:黄金分割比例倒数)。
全域散列法
一般情况下,哈希函数能将随机的输入均匀的映射到散列表的各个槽中。
但是如果有人恶意针对某个固定的哈希函数,故意输入n个关键字,被哈希函数映射到同一个槽中,那么平均检索时间退化为 Θ(n) 。
为了避免这种困境,我们将随机地选择哈希函数。这种方法称为:全域散列(universal hashing)。
当然,随机选择并不是乱选,而是从一组预先设计(全域的)的函数 H 中,随机地选择一个哈希函数 h。
设 H 为一组有限的散列函数,它们将关键字全域 U 映射到 {0, 1, …, m-1} 中。如果它们对每一对不同的关键字 k,l ∈ U,满足 h(k) = h(l) 的散列函数 h ∈ H 的个数至多为 |H|/m,那么这组函数 H 称为全域的(universal)。
这表明了两点性质:
- 如果从 H 中随机地选择一个散列函数,当关键字 k ≠ l 时,两者发生冲突的概率不大于 1/m。
- 这也正好是从集合{0, 1, …, m-1} 中独立地随机选择 h(k) 和 h(l) 时发生冲突的概率。
我们可以证明,全域散列法能均匀地将关键字映射进各个槽中。
如果 h 选自一组全域散列函数,将 n 个关键字散列到一个大小为 m 的表 T 中,并用链接法解决冲突。
- 如果关键字 k 不在表中,则 k 被散列到的链表的期望长度 E[nh(k)] 至多为 α = n/m。
- 如果关键字 k 在表中,则包含关键字 k 的链表的期望长度 E[nh(k)] 至多为 **1+ α**。
证明:
由于上述的性质1,我们知道:对于每一个关键字 k,其余关键字与之冲突的概率 ≤ 1/m。所以与 k 映射到同一个槽的关键字个数的期望为:n/m = α。
- 如果关键字 k 不在表中,则 k 被散列到的链表的期望长度至多为 α = n/m。
- 如果关键字 k 在表中,则计数时需要算上 k,所以再 +1。
如何设计一组全域哈希函数呢?
选择一个足够大的素数 p,使得每一个可能的关键字 k 都落在 [0, p-1] 。
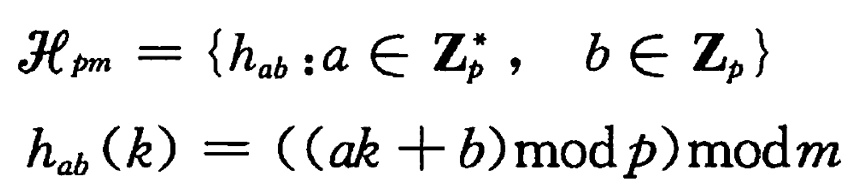
完全散列
当关键字集合是静态(static)时,散列技术也能提供出色的最坏情况性能。所谓静态,就是指一旦各关键字存入表中,关键字集合就不再变化了。
针对这一情形,我们采用:完全散列(perfect hashing)。
如果该方法进行查找时,能在最坏情况下用 O(1) 时间完成。
我们采用两级的散列方法来设计完全散列方案,在每级上都使用全域散列。
- 第一级与链地址法相同:从一组全域哈希函数中选出一个函数 h,将 n 个关键字映射到 m 个槽中。
- 第二级中,我们建立一个较小的散列表。
- 通过选取合适的哈希函数 hi,保证第二级散列表上不会发生冲突。(从一组全域哈希函数中随机选,如果冲突,则随机再选,直到选出。)
- 第二级散列表 Si 的大小 mi 总是被散列到槽中的元素个数 ni 的平方。
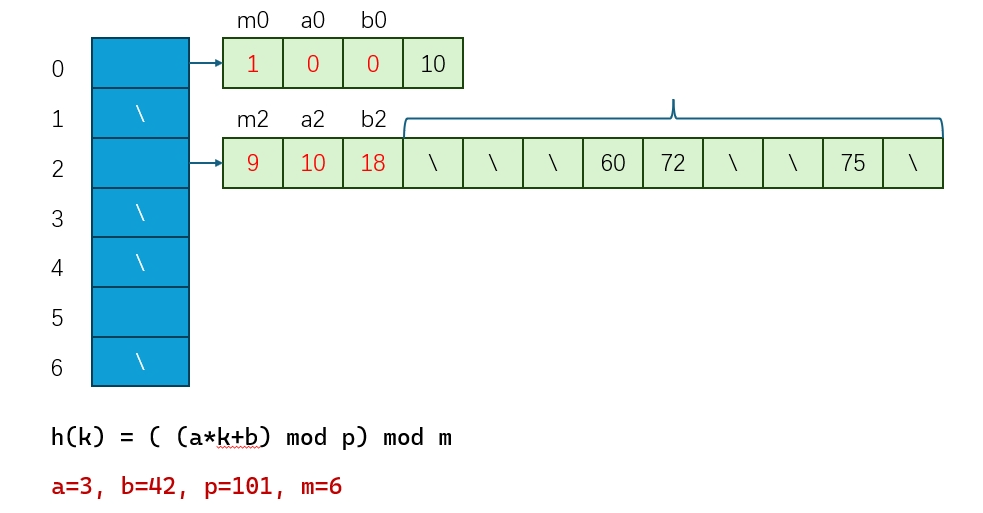
我们可以证明:在第二级散列表选取哈希函数时,比较容易选出一个哈希函数,不存在冲突。
如果从一个全域散列函数类中随机选出散列函数 h,将 n 个关键宇存储在一个大小为 m = n2 的散列表中,那么表中出现的冲突个数的期望小于 1/2。

此外,我们可以证明:通过合适地选取第一级哈希函数,预期使用的总空间大小为 O(n)。

python 代码实现如下:
1 | import random |
顺序统计量
最小值和最大值
在一个有 n 个元素的集合中,需要做多少次比较才能确定其最小元素呢?
最简单的方式:依次遍历集合中的每个元素,并记录下当前最小元素。这样会经过 n-1 次比较。进一步,如果我们希望同时找到最小值和最大值,如此方法则需要 2n-2 次比较。
但事实上,我们有更快速的方法,能同时找到最大值和最小值,且只需要 3[n/2] 次比较。
步骤如下:
- 将输入元素成对处理。对于每一对元素 a 和 b,相互比较。
- 将 a、b 中的较小者与当前最小值比较,将较大者与当前最大值比较。这样,每对元素需要3次比较。
在此基础上,比较次数可以进一步缩减到 **O(logn)**。
步骤如下:
- 递归处理:每次能将最大值、最小值所在集合的范围缩小一半。
1 | def find_min_max(arr): |
选择算法
在一个有 n 个元素的集合中,如何找到第 i 小的元素呢?
期望为线性时间的选择算法
RANDOMIZED-SELECT 是一个分治算法,用于在数组中找到第 i 小的元素。这个算法是基于快速排序的分区操作 RANDOMIZED-PARTITION 的,但它只递归地处理分区的一边,而不是两边。这使得 RANDOMIZED-SELECT 的期望运行时间为 **O(n)**,这比快速排序的 O(n · log n) 要好。
步骤如下:
- 边界检查:如果子数组的范围
p和r相等,说明已经找到了第i小的元素,直接返回。 - 随机分区:使用
RANDOMIZED-PARTITION对数组A[p..r]进行分区,返回分区的基准索引q。 - 计算基准位置:计算枢轴元素相对于子数组起始位置
p的位置k。 - **比较
i和k**:如果i等于k,则枢轴元素就是第i小的元素,返回A[q]。如果i小于k,则在左子数组A[p..q-1]中递归寻找第i小的元素。否则,在右子数组A[q+1..r]中递归寻找第i-k小的元素。
伪代码如下:
1 | RANDOMIZED-SELECT (A, p, r, i) |
最坏情况为线性时间的选择算法
因为随机选可能很倒霉
我们给出一个选择算法 SELECT,最坏情况仍为线性时间。
步骤如下:
- 分组:将数组分为大约
n/5组,每组包含5个元素。如果有剩余元素(即n % 5不为0),则形成最后一组。 - 寻找每组的中位数:对每组进行插入排序(或其他线性时间排序),然后选择每组的中位数。
- 递归寻找中位数的中位数:对所有组的中位数进行递归调用
SELECT算法,找到它们的中位数x。 - 划分数组:使用
x作为主元,X是区间里第k小的元素,对整个数组进行划分。划分后,数组被分为低区(元素小于x)、中区(元素等于x)和高区(元素大于x)。 - 递归选择:根据
i的值,决定是在低区、中区还是高区递归调用SELECT算法:- 如果
i等于k(x在数组中的位置),则返回x。 - 如果
i小于k,则在低区递归调用SELECT。 - 如果
i大于k,则在高区递归调用SELECT,且i = i-k。
- 如果
图片
我们下面分析该算法的运行时间,证明:其在最坏情况下,运行时间仍为 **O(n)**。
证明
Scheduler
堆排序
堆
堆是一个数组,存储在数组中的二叉树。堆可以看成一个近似的完全二叉树,除了最底层外,该树是充满的。
堆可以分为两类:
- 最大堆:父节点 > 子节点
- 最小堆:父节点 < 子节点

堆排序
堆排序的时间复杂度也是 O(n·lgn)。但是,不同于归并排序,堆排序具有空间原址性:只需要常数个额外空间来存储临时数据。
为了实现堆,我们要实现以下两个函数:
MAX-HEAPIFY():最大堆化函数,时间复杂度 **O(lgn)**。BUILD-MAX-HEAP():建立最大堆函数,时间复杂度 **O(n)**。
堆化
1 | # python代码 |

需要注意:当对 i 节点调用MAX-HEAPIFY()时,只有当其左右子树都是最大堆时,调用后,i 节点开始的树才是最大堆。
直观上,不难发现MAX-HEAPIFY()的时间复杂度是:**O(lgn)**。
建堆
1 | # python代码 |
粗略的看,每次调用max_heapify()函数的时间开销是**O(lgn),总共调用了O(n)次,所以build_max_heap()的时间复杂度应该是:O(n·lgn)**。
但是由于:底层节点调用max_heapify()的时间复杂度实际上是**O(h),远远小于O(n),且底层节点数量更多,时间开销接近O(lgn)的高层节点数量很少。所以,build-max-heap()的时间复杂度比O(n·lgn)更小,是O(n)**。
推导如下:
高度为h的节点最多有 [n/2h+1] 个。

因此,我们可以在线性时间内,把一个无序数组构造成为一个最大堆。
堆排序
堆排序的过程:
- 在整个数组上建立最大堆。
- 数组的第一个元素(待排序序列中的最大元素),与待排序序列的最后一个元素交换。
- 堆大小(也是待排序序列长度)减1。
- 对堆顶元素(数组第一个元素)调用
max_heapify函数,保证新的堆仍是最大堆。 - 如此,排好了原序列中的最大元素,且新序列仍是最大堆。如此循环即可。
1 | # python代码 |
堆排序的时间复杂度:**O(n·lgn)**。
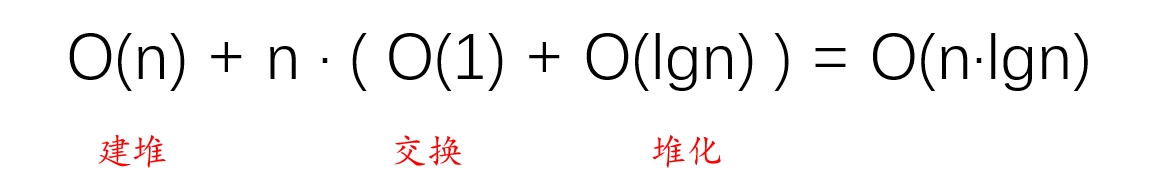
优先队列
优先队列是一种数据结构,维护由一组元素,支持插入和删除最大元素(或最小元素)。
一个最大优先队列支持以下操作:
| 函数 | 描述 | 时间 |
|---|---|---|
| INSERT(S,x) | 把元素 x 插入集合 S 中。 | O(lgn) |
| MAXIMUM(S) | 返回 S 中具有最大元素。 | O(1) |
| EXTRACT-MAX(S) | 去掉并返回 S 中的具有最大元素。 | O(lgn) |
| INCREASE-KEY(S, x, k) | 将元素 x 增加到 k(假设k>x) | O(lgn) |
需要注意:
- 堆并不一定是是二叉堆,二叉堆只是常见且易于用数组实现而已。
- 最大堆(二叉堆)只是优先队列的一种实现方式。
1 | # python code |
快速排序
快速排序
快速排序也是一种分治算法。
快速排序分为三步:
- 分解:数组
A[p.. r]被划分为两个(可能为空)子数组A[p.. q-1]和A[q+ 1.. r]。A[p .. q-1]中的每一个元素都小于等于A[q]。A[q]也小于等于A[q+1..r]中的每个元素。
- 解决:对划分出的两个子数组,分别递归调用快速排序。
- 合并:由于子数组都是原址排序的,所以不需要合并操作。
伪代码如下:
1 | QUICKSORT(A, p, r) |
1 | PARTITION(A, p, r) |
图片
快排性能
最坏情况
当划分产生的两个子问题分别包含了 n-1 个元素和 0 个元素时,快速排序的最坏情况发生了。
此时运行时间的递推公式为:
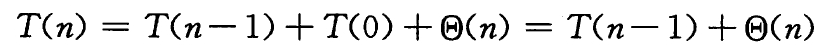
我们通过归纳法,可以证明:最坏情况下,快速排序的运行时间为 **Θ(n2)**。
此外,当输入数组已经完全有序时,快速排序的时间复杂度仍然为 **Θ(n2)**。
最好情况
在可能的最平衡的划分中,PARTITION 得到的两个子问题的规模都不大于 n/2。
此时运行时间的递推公式为:
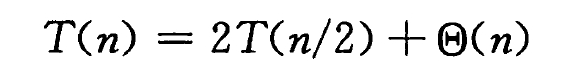
我们通过主定理,可以证明:最好情况下,快速排序的运行时间为 **Θ(n · lgn)**。
一般情况
快速排序的平均运行时间更接近于其最好情况,而非最坏情况。
我们举例说明:
例子
随机化的快排
在讨论快速排序的平均情况性能的时候,我们的前提假设是:输入数据的所有排列都是等概率出现。但在现实中,这个假设并不总是成立的。所以对于一些输入,快排的最坏情况可能经常发生。
为了避免,我们引入随机化版本:每次划分时,随机选择基准(pivot)。
伪代码如下:
快排函数:几乎没有变化,只是将划分函数
PARTITION替换为新的RANDOMIZED-PARTITION。
1 | RANOOMIZED-QUICKSORT CA, p, r) |
划分函数:从子数组中随机选择基准
1 | RANDOMIZED-PARTITION (A, p, r) |
随机算法
随机算法
对于一个算法,它的平均执行速度很快,但很可能存在一些特定的输入,使得算法效率很低。如果这样的输入经常出现,那么算法的实际执行效率就会低于期望的效率。为了避免这样的情况,我们常常采用随机算法。
不失一般性地,假设给定一个数组 A,包含元素 1~n,我们讨论如何构造 A 的随机排列。
注意:我们让随机发生在算法上,而不是在输入分布上。
Permute-By-Sorting
一个通常的方法是:
- 为数组的每个元素 A[i] 赋一个随机的优先级 P[i],
- 然后依据优先级对数组 A 中的元素进行排序。
1 | import random |
这种随机算法的时间复杂度取决于排序算法的选择。如果采用的是归并、快排,那么时间复杂度可以达到 **O(n·lgn)**。
Randomize in Place
产生随机排列的更好方法是:原址排列给定数组。
过程如下:
- 在进行第 i 次迭代时,元素 A[i] 是从元素A[i] 到 A[n] 中随机选取的。
- 且第 i 次迭代以后, A[i]不再改变。
1 | import random |
Allocator
技术路线
Allocator
操作系统位于硬件和软件之间,为用户程序提供底层硬件资源的抽象。操作系统提供必要的系统调用(system calls)。从而,用户程序不必再考虑如何使用硬件,而是通过这些 system calls 来调用硬件资源。

当我们编写 c 语言程序时,我们可以直接通过 malloc() 和 free() 函数,简洁地申请和释放内存空间。但是 malloc() 和 free() 实际上并没有申请内存的权限,而是请操作系统的内核(kernel)帮忙。kernel 将malloc()所需的内存分配好并给它。所以,真正负责分配内存空间的是内核的allocator(分配器)。
allocator(分配器)是一种用于管理内存资源的机制。它负责在操作系统与应用程序之间调度和分配内存。内存分配器通常与动态内存管理有关,允许程序在运行时申请和释放内存。
具象的说:allocator就是负责内存分配的系统调用函数。
我们希望实现4个系统调用函数:
void kinit():初始化内存空间void* kalloc_page():分配新的页void kfree_page(void* p):释放页void* kalloc(unsigned long long size):分配指定大小的内存块void kfree(void* ptr):释放指定的内存块
请注意
kfree()、kfree_page()接口的隐含意义:在释放空间时,用户不需告知库这块空间的大小。因此,在只传入一个指针的情况下,allocator必须能够弄清楚这块内存的大小。
Free-space management
如果需要管理的空间被划分为固定大小的单元,就很容易。
就像:内存空间按页(Page)划分,内存由若干页组成。一页通常为4KB(4096 bytes)。
如果要管理的空闲空间由大小不同的单元构成,管理就变得困难而有趣。
这种情况出现在:用户级的内存分配库,如
malloc()和free(),或者操作系统用分段(segmentation)的方式实现虚拟内存。
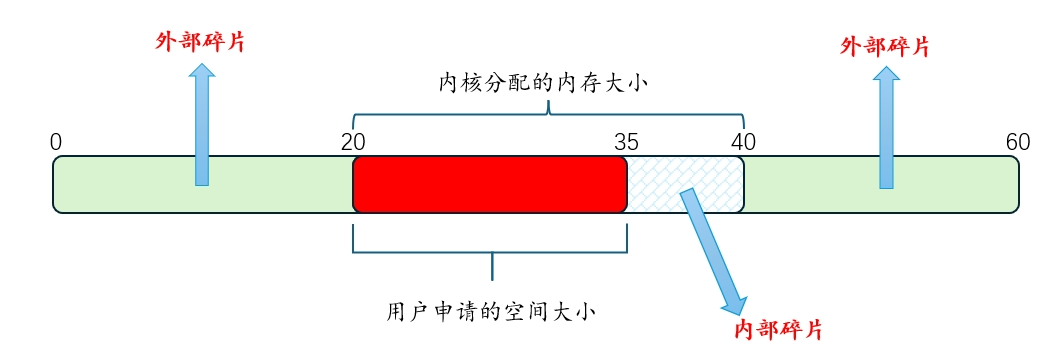
对于第二种情况,出现了外部碎片(external fragmentation)的问题:空闲空间被分割成不同大小的小块,成为碎片,后续的请求可能失败,因为没有一块足够大的连续空闲空间,即使这时总的空闲空间超出了请求的大小。
例如在下图中,全部可用空闲空间是60字节,但被切成两个20字节大小的碎片,导致一个25字节的分配请求失败。
我们主要关心的是外部碎片。但是,分配程序也可能有内部碎片(internal fragmentation)的问题。如果分配程序给出的内存块超出请求的大小,在这种块中超出请求的空间(因此而未使用)就被认为是内部碎片(因为浪费发生在已分配单元的内部),这是另一种形式的空间浪费。
但是,简单起见,这里主要考虑外部碎片。
Mechanism
allocator管理的空间由于历史原因被称为堆(heap),在堆上管理空闲空间的数据结构通常称为空闲列表(free list)。该结构包含了管理内存区域中所有空闲块的引用(也就是:地址)。当然,该数据结构不一定真的是列表,而只是某种可以追踪空闲空间的数据结构。
我们先以页为单位讨论。
freelist本质上是一个指针,指向第一个空闲页的开始地址。每个空闲页开头存放一个指针run,指向下一个空闲页。最后一个空闲页的run指针指向NULL。
1 | // 空闲物理页节点 |
当allocator初始化时:allocator本应该将所有物理内存分页,存进freelist中。但是由于物理地址刚开始处存放着内核代码,所以allocator会把内核代码结束处以后的所有地址空间分页。
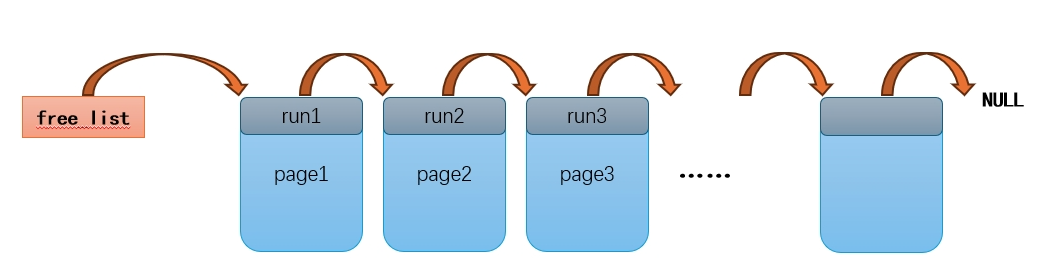
当用户程序向allocator申请page时:allocator返回freelist,也就是将freelist指向的第一个page分配给它。然后freelist = run1,也就是使freelist指向下一个空闲页。如此,第一个页“page1”就被分配给用户程序了。需要注意的是:allocator不关心已分配的页,已分配的页由各个申请的用户程序管理。且已分配的页不用再维护run指针,所以整页都是可以使用的(只有空闲页才需要在页头写上run指针)。
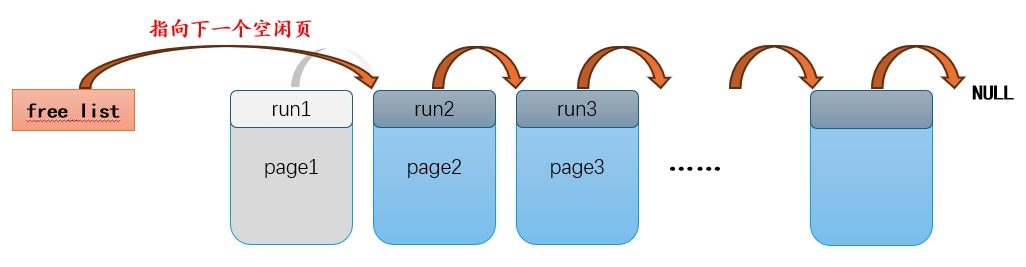
当用户程序向allocator释放page时:allocator将返还的page添加到当前链表的第一个,也就是:freelist=被释放的页的地址。然后:被释放页的run指针=原先freelist的值。
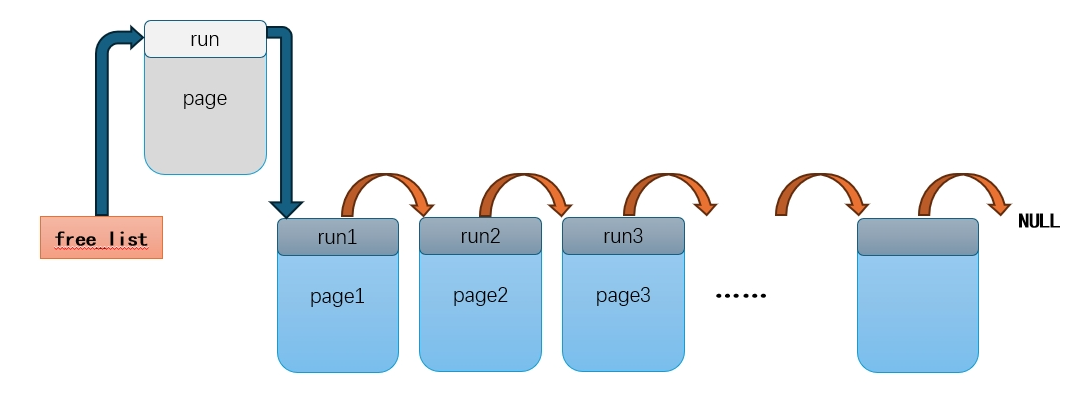
以上,我们都是以页为单位,讨论内存分配。但是申请的内存可能很小,远远不足一页。
最朴素的想法就是:我们需要把一页的内存,按不同大小需求,划分成不同小块。
已分配的内存块:
我们需要保证分配出去的内存能被回收。由于
void kfree(void* ptr)函数参数只告诉了地址指针,并没有告诉大小。所以每个内存块需要存储其大小size和一些必要信息magic,即每个内存块都需要有一个头部(header)。如此,当kfree()时:我们读取ptr指向处的往前若干字节就能知道需要释放的内存空间。未分配的空间:
类似页于与页之间的
freelist,我们也会在页内维护一个这样的freelist。
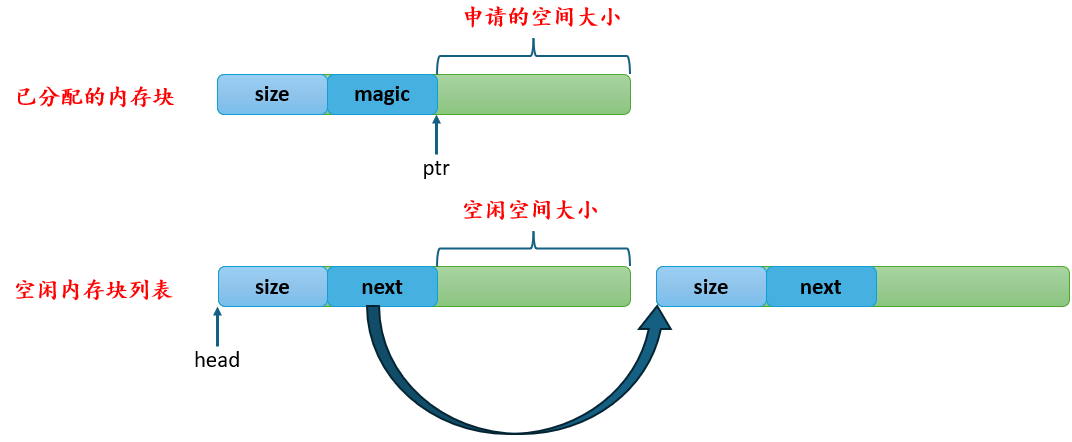
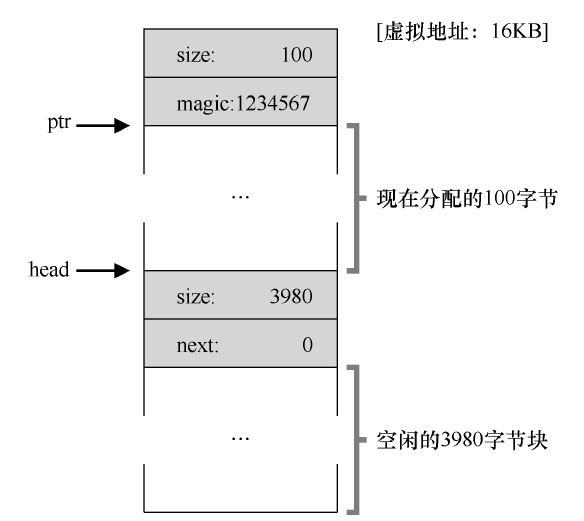
但是,如此分配内存空间后,即便使用过的内存块都被释放,空闲列表里也是一串串大小不一的内存碎片。而且它们在链表里的顺序是随机的,并不是按照地址从小到大排列的,由它们被用户程序释放的顺序所决定。
之所以会这样,是因为:我们忘了合并(coalesce)列表项,虽然整个内存空间是空闲的,但却被逐渐分成了小块,因此形成了碎片化的内存空间。
事已至此,那如何在内存池(freelist中的空闲内存块)中找到符合要求的内存块呢?且我们希望能保证:快速和碎片最小化。
常见的内存分配算法:
- 首次适配(First-fit):在内存池中找到第一个满足需求的空闲块并分配。
- 最佳适配(Best-fit):寻找最接近所需大小的空闲块进行分配,以减少剩余的空闲空间。
- 最坏适配(Worst-fit):选择最大的空闲块分配,保留较大的剩余空间。
- 快速适配(Quick-fit):预先分配若干种常用大小的内存块,减少分配和释放的时间。
Segregated list
为了解决内存碎片化的问题,我们采用分离空闲列表(segregated list),也就是:厚块分配程序(slab allocator)。
基本想法很简单:如果某个应用程序经常申请一种(或几种)大小的内存空间,那就用一个独立的列表,只管理这样大小的对象。其他大小的请求都一给更通用的内存分配程序。
首先我们介绍基本概念:
Cache(缓存):SLAB 分配器为特定类型的对象创建缓存,缓存包含多个对象,这些对象的大小是固定的。缓存是预分配的内存块的集合,便于频繁创建和销毁相同类型的对象。
Slab(厚块):Slab 是 cache 中的组成单元,每个 cache 包含多个 Slab。Slab 是一组预分配的内存块,包含了若干个固定大小的对象块(即 object),用于保存对象。一个 Slab 可以是空闲的、部分使用的或者完全使用的。Slab 通过内存池预先分配内存,以便快速提供给请求的对象。
Object(对象):分配器管理的最小内存单元或内存块,被称为 object。每个 object 是一块固定大小的内存,用来存储具体的数据结构或对象。通过 Slab allocator,内存被分配为一个个 Slab,而 Slab 中则由若干个相同大小的 object 组成。
1 |
|
具体来说:
- 在内核启动时,它为可能频繁请求的内核对象创建一些缓存。这些的对象缓存每个分离了特定大小的空闲列表,因此能够很快地响应内存请求和释放。
- 如果某个缓存中的空闲空间快耗尽时,它就向通用内存分配程序申请一些内存厚块(slab)(总量是页大小和对象大小的公倍数)。
- 相反,如果给定厚块中对象的引用计数变为0,通用的内存分配程序可以从专门的分配程序中回收这些空间,这通常发生在虚拟内存系统需要更多的空间的时候。
代码实现
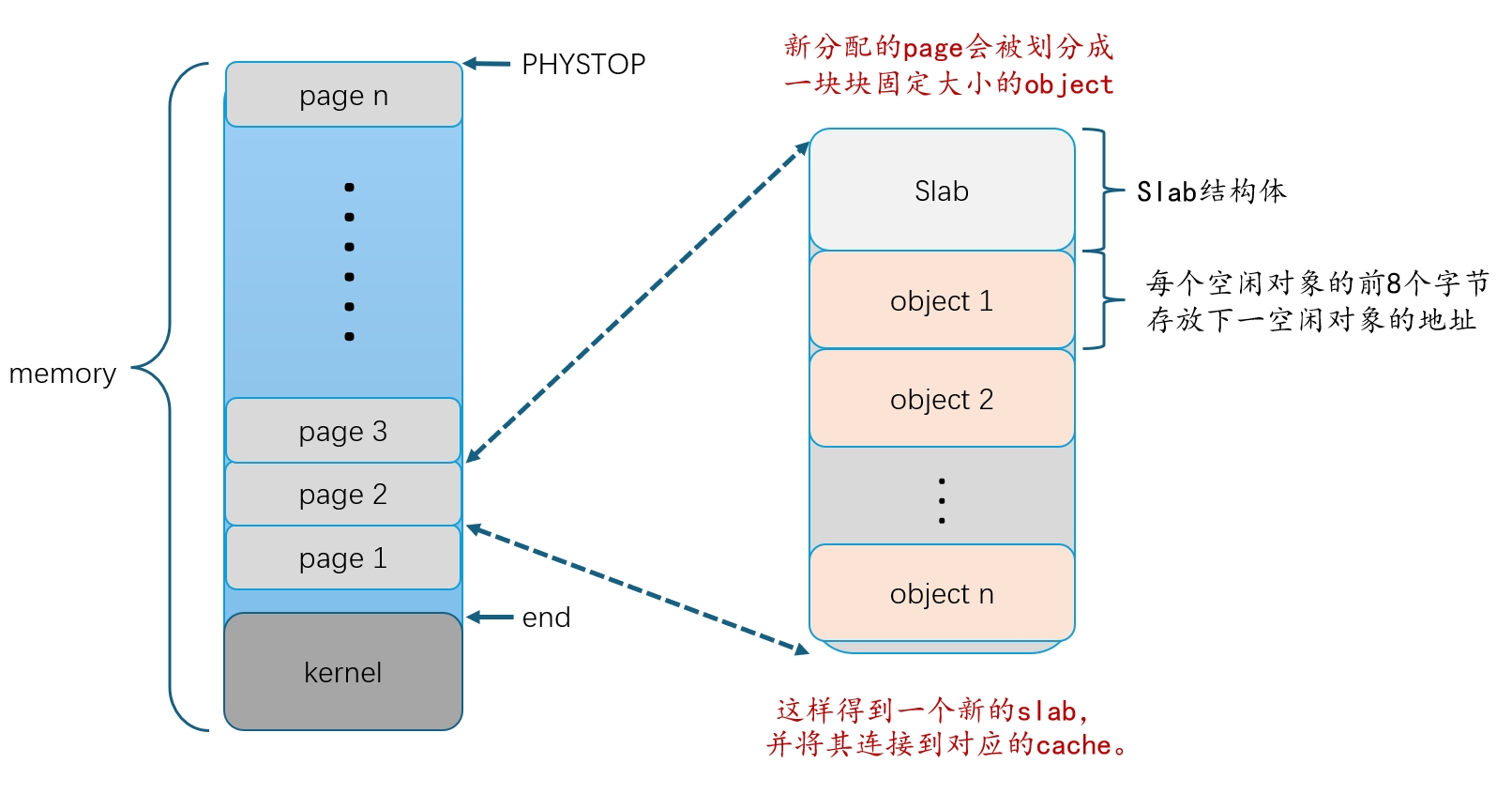
kinit()
初始化时,我们将始于end止于PHYSTOP的堆地址空间全部分页,并把他们连接到kmem结构体中的freelist。
注意:end是内核地址空间的终止处,但不一定是4KB的倍数。对于end所在页没有用完的部分,我们弃之不用。我们从大于end的最小的4KB倍数的地址处开始分页,直至物理地址终点处PHYSTOP。(所以上图中end和page1之间并不是直接相接的,可能有空余空间。)
1 | void kinit() { |
1 |
|
kalloc_page()
由于计算机可能是多核运行,可能同时多个进程申请空间。为了避免将同一页分配给多个进程,我们要加锁保持一致性。
1 | void* kalloc_page() { |
kfree_page()
将指针p所指的页添加会页的空闲列表。
1 | void kfree_page(void* p) { |
slab_alloc()
给定cache,也就是给定对象大小,我们在一串串slab中寻找空闲对象,并返回其地址。如果cache中的所有slab都没有空闲对象,那么我们调用kalloc_page()申请新的页,并将其划分成新的slab,在返回新slab中的第一个对象的地址。
注意:
- 当我们把新的一页划分后得到slab时,由于每个slab的开头需要存放
Slab结构体(25字节,但是为了对齐需要32字节)在开头,所以剩下4064字节用于划分对象。对象大小并不一定总是能整除剩余空间大小,所以是有可能划分完所有对象后,存在碎片空间。 - 对齐
1 | void* slab_alloc(struct Cache* cache) { |
slab_free()
给出对象地址,我们将其添加会对应slab的空闲对象列表中。
注意:由于slab是由页划分得来的,所以slab的其实地址都是4KB的倍数。而且,每个slab的开始处存放着struct Slab结构体。所以我们只需要求出:小于obj的最大的4KB倍数(这就是该slab的Slab结构体地址)。
1 | void slab_free(void* obj) { |
kalloc()
分配指定大小的内存块。我们通过调用slab_alloc()来分配适当大小的内存块。
1 | void* kalloc(unsigned long long size) { |
kfree()
释放指定地址的内存块。我们直接通过调用slab_free()把内存块添加会空闲对象列表,这样这个内存块就再被其他程序申请使用了。
1 | void kfree(void* ptr) { |
参考资料
[教材OSTEP第17章:空闲空间管理](Operating Systems: Three Easy Pieces (wisc.edu))